|
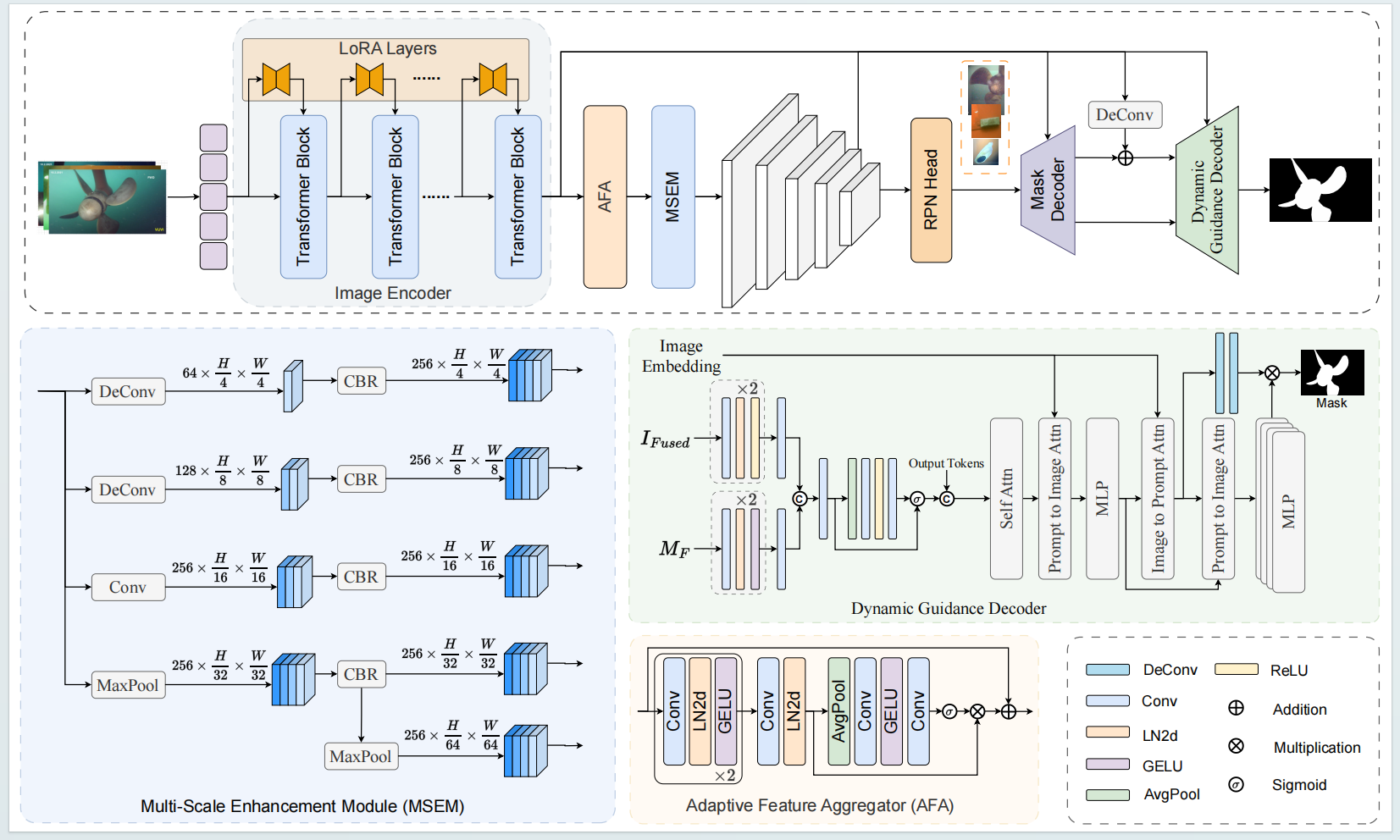
The architecture of the proposed Boundary-Aware Distracted Attention Network for Camouflaged Object Detection (DGD-SAM).
Abstract
With the growing demand for deep-sea exploration and marine resource exploitation, underwater vision
technologies have become a critical enabler for applications, such as robotic operations and marine
biological monitoring. Among various vision tasks, Underwater Image Instance Segmentation (UIIS) is
particularly challenging, as it requires both precise object localization and pixel-level mask
generation. In recent years, vision foundation models, in particular, the Segment Anything Model (SAM),
have demonstrated remarkable zero-shot generalization capabilities in generic scenes. However, their
performance remains unsatisfactory in complex underwater environments. Severe light absorption and
scattering in underwater environments lead to significant image degradation, including color distortion,
extremely low contrast, and blurred boundaries, which substantially hinder effective feature extraction.
Moreover, the segmentation performance of SAM heavily relies on manually provided explicit prompts
(e.g., points, boxes, and masks). This dependency not only increases annotation costs but also limits
its applicability in unattended or complex underwater scenarios. To address these challenges, we propose
a Dynamically-Guided SAM (DGD-SAM). By introducing a dynamically-guided mechanism and integrating
feature aggregation with a multi-scale feature enhancement module, DGD-SAM establishes a complete
pipeline for automatic prompt generation and refined segmentation. First, to mitigate the feature
distribution discrepancy between detection and segmentation tasks, an Adaptive Feature Aggregator (AFA)
is designed. This module re-models inter-channel dependencies through a channel attention mechanism,
achieving task alignment across both spatial and channel dimensions and effectively enhancing the
model’s sensitivity to weak underwater targets. Second, considering the large variation in underwater
target scales and the complexity of background interference, a multi-scale feature enhancement module is
constructed. By building a cross-resolution feature pyramid, this module significantly improves the
model’s ability to capture targets of various scales in complex scenes. During the decoding stage, a
Dynamically-Guided Decoder (DGD) is proposed, which first integrates the initial segmentation mask with
image features to generate dynamic guidance information, and then performs refined mask prediction
through bidirectional attention interactions between the prompts and image features. Experimental
results demonstrate that DGD-SAM consistently outperforms state-of-the-art methods on four public
underwater data sets, including LIACI, USIS10K, UIIS, and UIIS10K, as well as two terrestrial scene data
sets, i.e., COME15K-E and COME15K-H. These results indicate that the proposed method not only achieves
superior performance in underwater environments but also maintains stable and competitive segmentation
performance in terrestrial scenes, suggesting that the model does not overly rely on scene-specific
characteristics and exhibits strong generalizability and scalability.
Links


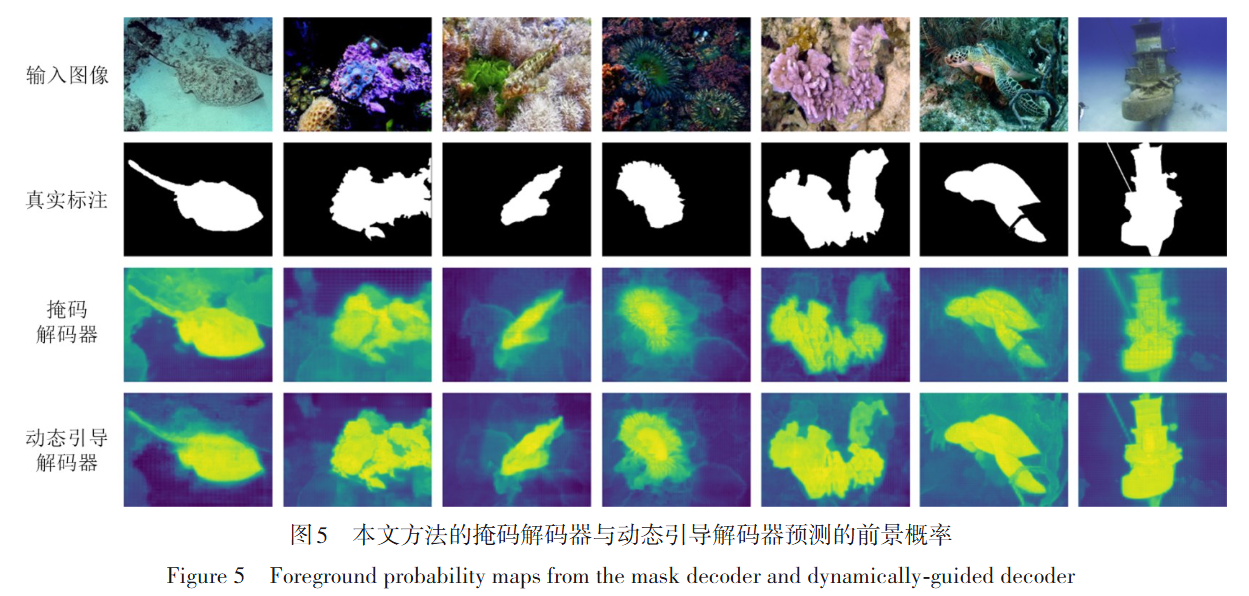
Experimental Results

|
|
Citation
@article{尚毅涵 2026 DGD-SAM:一种用于水下图像实例分割的动态引导SAM,
title={DGD-SAM:一种用于水下图像实例分割的动态引导SAM},
author={尚毅涵 and 董兴辉},
journal={电子学报},
pages={1-13},
year={2026},
doi={10.12263/DZXB.C251002.R1},
}